Streamlining Webhook Handling
How we improved our process of handling webhooks.
Webhooks play a crucial role in enabling real-time communication and integration between systems. At Jodo, our initial approach to processing webhooks through our regular API server led to performance issues, affecting our customer experience. These webhooks, often received in bulk, would sometimes overwhelm our servers, causing delays and disruptions. This post outlines the challenges we faced, the solutions we implemented, and the benefits of our improved webhook handling process.
Challenges We Faced
The diagram below illustrates how we used to handle requests before improving our system.
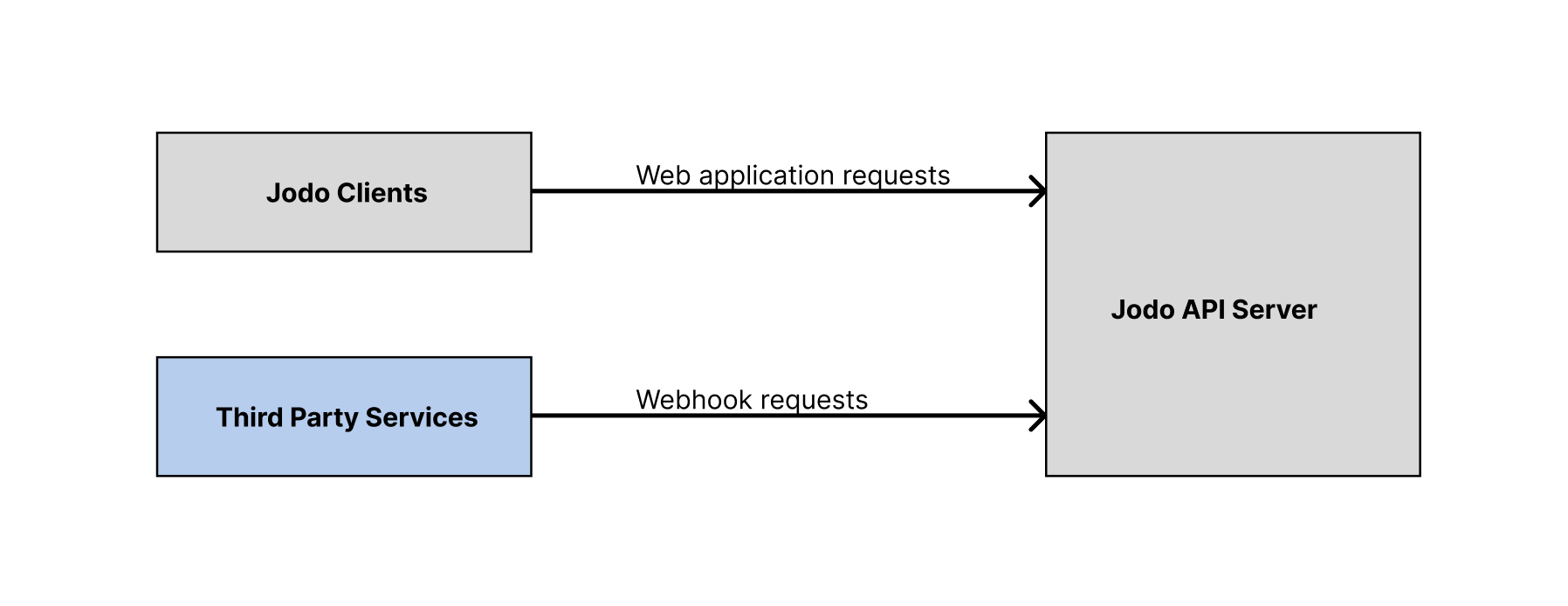
As shown in Fig 1, our initial setup involved processing webhook requests through the same API server that handled client application requests. This setup resulted in several issues:
- Server Overload: High volumes of webhooks often caused our API server to choke, leading to performance degradation.
- Impact on Customer Experience: As the API server was also responsible for handling client requests, any delay or failure in processing webhooks directly affected our customers.
- Bulk Webhook Traffic: The nature of some events meant that webhooks were received in bulk, exacerbating the overload problem.
Solution: Asynchronous Processing
A crucial realization in our journey was the importance of quickly acknowledging the webhook sender while deferring the processing to an asynchronous system. This approach not only improved response times but also ensured data integrity and reliability, even in the face of service disruptions.
Solutions Implemented
To address the challenges in our initial setup, we adopted a new approach that leverages an API Gateway, SQS, Lambda functions, Kafka, and S3. Here’s how we restructured our webhook handling process:
API Gateway
- Acts as an entry point for all webhook requests.
- Immediately puts incoming webhook messages into an SQS queue (Catchall) and returns a 200 response to the caller, ensuring quick acknowledgment.
Lambda Function
- Processes messages from the catchall SQS queue.
- Routes the messages based on the third-party source.
- Places the messages into relevant third-party specific SQS queues.
- Dumps request details into S3 for persistent storage and audit trails.
Workers
- Subscribe to the specific SQS queues.
- Consume and process the messages.
- Utilize Kafka for increased concurrency if needed, managing the load on shared resources like the database, cache, and core services.
Benefits Achieved
This new architecture brought several key improvements:
Dedicated Interface for Webhook Requests
The API Gateway provides a specialized interface for handling webhook requests, separating them from client requests and ensuring better performance for both.
Controlled Concurrency
By using workers that subscribe to Kafka topics, we can control the concurrency at which messages are processed. This results in a predictable load on shared resources, such as the database, cache, and core services.
Reliability and Reusability
In the event of failures, the system does not lose messages. The messages stored in SQS and Kafka provide the ability to replay them when needed, ensuring data integrity and reliability.
Improved Architectural Diagram
Here is an improved architectural diagram illustrating the new webhook handling process:
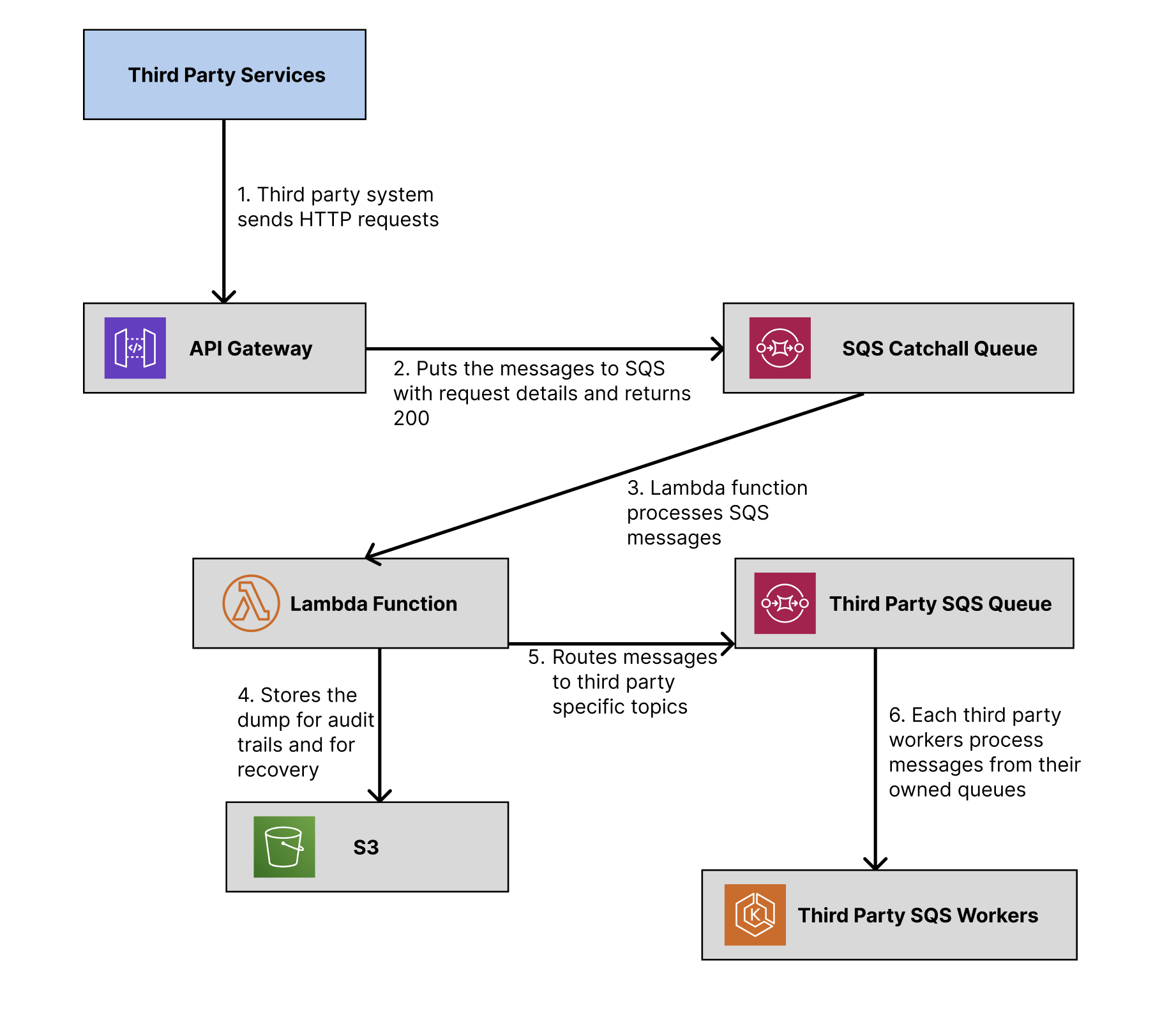
- Third Party Service sends webhook requests to the API Gateway.
- API Gateway puts messages into the Catchall SQS Queue and returns a 200 response.
- Lambda Function:
- Processes messages from the Catchall SQS Queue.
- Routes and places messages into relevant SQS queue.
- Dumps request details into S3.
- Workers:
- Subscribe to SQS queues.
- Consume and process messages, managing concurrency to ensure predictable load.
Conclusion
Revamping our webhook handling process has significantly enhanced the efficiency, reliability, and security of our system. By adopting asynchronous processing and implementing a scalable, resilient infrastructure, we have improved our customer experience and ensured data integrity. We hope our journey and solutions provide valuable insights for others facing similar challenges.
If your organization is struggling with webhook handling, consider evaluating your current setup and implementing some of the strategies we discussed. We’d love to hear about your experiences or answer any questions you might have!
By sharing our journey and the steps we took to improve webhook handling, we aim to help others facing similar issues. Implementing these changes has not only improved our system’s performance but also enhanced our team’s ability to manage and troubleshoot webhooks effectively.
Thanks to Bibek Rauniyar, Shwetanshu Mehta, and Johnbabu Koppolu for their valuable inputs and contributions. Their expertise and dedication were instrumental in the successful revamp of our webhook handling process.
The original version of this post appeared at Jodo’s Engineering Blog
