How we achieved MySQL HA using ProxySQL
Thoughts on ProxySQL, HAProxy for MySQL

ProxySQL is an open source MySQL load balancer and proxy solution which can run on almost any Linux distributions. It can be used to improve performance and availability of MySQL server. In this post, we’ll discuss a general overview of what ProxySQL is and examples of how it can be used to improve the performance and availability of your MySQL servers.
First, let’s see how ProxySQL can be useful. Let us assume you have an application which uses a single MySQL host with a database of five tables – Users, Settings, Posts, Comments and Messages. Your application performs all operations on the single database server; but as time goes by the number of the users using the application increases. To handle the scaling traffic, you add new application servers behind the load balancer and let them autoscale. This works well till a point after which all operations on your database system become slow, may be because of the database size, the number of requests or just bad joins. Or sometimes the database system goes down making the entire application unavailable.
You can tackle this problem if you remove this single point of failure – the dependency on the single database. You could take multiple approaches to redesign your database implementation – you can split tables based on its usages and place these tables in separate hosts. In the above example, you have some big tables (eg. Posts, Comments and Messages) and some small tables (eg. Users, Settings). This separation can be done based on how tables are being used. There could be some tables that are read heavy and very light on writes, while the rest are write intensive. You could split based on that. Or some tables might be very critical in nature because they are used the critical application path, while the rest are used for archiving by background processes. You could split based on this too.
However, both of these would require considerable application code changes. More often than not, you might not have the luxury of time for such a rewrite or the rewrite might be non-trivial. This is where ProxySQL comes to the rescue, with little or no code changes! Of course, this is not the only scenario ProxySQL can help you with. It also helps in multiple other areas such as performance and security, but this is one of the complex problems ProxySQL helps solve elegantly.
What is ProxySQL?
ProxySQL is an open source tool written in C++ and part of it is written in Python by René Cannaò . As the name explains, it’s a proxy service that gets MySQL request from clients and passes it onto the backend services and passes the result received to the requestor. You can route SQL queries to multiple databases based on rules and you can monitor queries, performance and the stats which can be helpful in optimising your application.
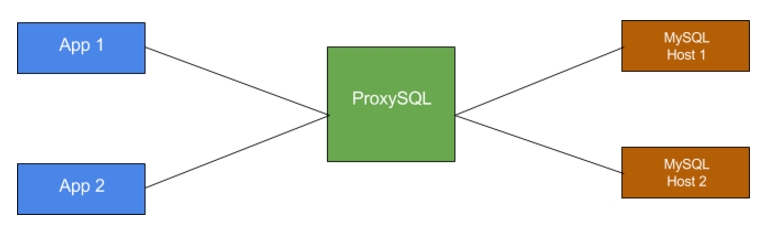
In above diagram, there are two different apps connecting to ProxySQL. ProxySQL routes queries to hosts based on some rules. These rules can be defined using simple regex and can be disabled or enabled using the admin console. You can get the list of things which can be controlled using query rules here.
Why ProxySQL?
ProxySQL is a network proxy that sits transparently between the database and application to solve:
- On the fly rewrite of queries
- Caching reads outside the database server
- Load balancing
- Query routeing and read/write split
- High availability
In ProxySQL, all backend servers are grouped into host groups, and each host group has logical functionality. For example, you can have host group HG1 for write masters, host group HG2 for read slaves, host group HG3 for ad-hoc query slaves and host group HG4 for test servers. A query is always routed to a single host group. Rules in ProxySQL governs where the query will be sent to available hosts.
How we use it at Exotel?
We at Exotel use ProxySQL to manage MySQL for sync and async services. There are two different approaches that can be followed here:
- ProxySQL as a centralised server
- ProxySQL on app instances
Each approach has its advantages and disadvantages so let’s discuss each one of them.
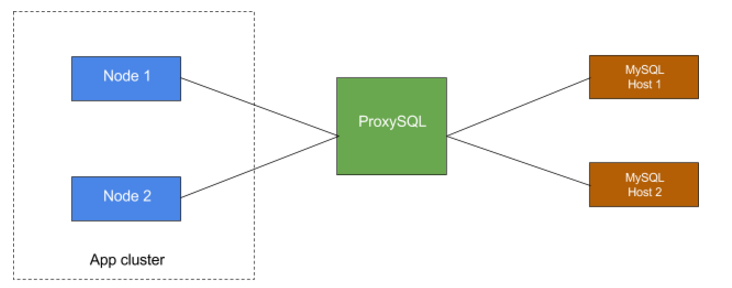
1. ProxySQL as a centralised server
ProxySQL as a centralised proxy server brings fast configuration control. But this approach introduces a single point of failure since your application queries will be routed via centralised proxy so if the proxy is down, all applications will be affected. This approach is useful and makes sense when you have some async services connecting to your DBs since recovery is possible in this case. Below is the diagram of this setup:
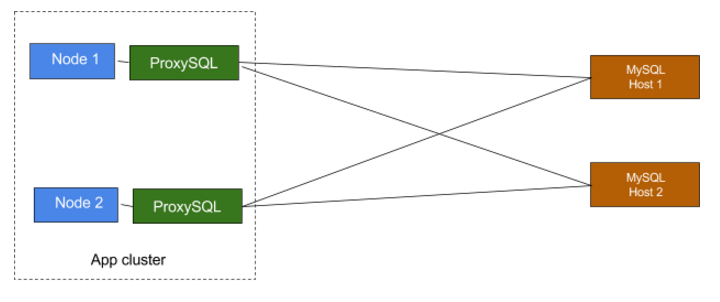
2. ProxySQL on app instances
Running proxy server locally on app instances helps us in removing the single point of failure. If one of the proxy server’s is down, it doesn’t affect other nodes. We follow this approach with all our sync services. Below is the diagram of this arrangement, where local ProxySQL(running on app instance) is connecting to host of their choice:
How ProxySQL works?
ProxySQL has basically one endpoint (default port is 6033 for clients and 6032 for admin interface) exposed to external services where it listens to the request same as how MySQL does. Clients can communicate to it via TCP protocol and it understands all the requests that MySQL can understand. Below is the pictorial representation of configuration system of ProxySQL.
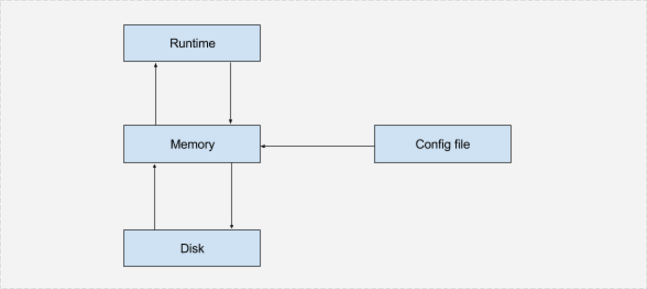
All functionalities of ProxySQL are achieved by a multi-layer configuration system where settings are moved from one layer to another. Let’s discuss each layer individually-
Runtime
It represents the in-memory data structures of ProxySQL used by the threads that are handling the requests. These contain the values of the global variables used, the list of backend servers grouped into host groups or the list of MySQL users that can connect to the proxy.
Memory
This represents an in-memory SQLite3 database which is exposed to the outside via a MySQL-compatible interface. Users can connect with a MySQL client to this interface and query different tables and databases. The configuration tables available through this interface are:
- mysql_servers - the list of backend servers
- mysql_users - the list of users and their credentials which can connect to ProxySQL. Note that ProxySQL will use these credentials to connect to the backend servers as well
- mysql_query_rules - the list of rules for routeing traffic to the different backend servers. These rules can also cause a rewrite of the query, or caching of the result
- global_variables - the list of global variables used throughout the proxy that can be tweaked at runtime.
- mysql_collations - the list of MySQL collations available for the proxy to work with. These are extracted directly from the client library.
- [only available in debug builds] debug_levels - the list of types of debug statements that ProxySQL emits together with their verbosity levels. This allows us to easily configure at runtime what kind of statements we have in the log in order to debug different problems. This is available only in debug builds because it can affect performance.
Disk and Config files
Disk represents an on-disk SQLite3 database, with the default location at $(DATADIR)/proxysql.db. Across restarts, the in-memory configs that were not persisted will be lost, therefore it is important to persist the configuration into a disk.
High availability
When in a host group one node A fails, all connections to A will be terminated and the node marked unhealthy. This is achieved by pinging each node for the health check.

By goal, ProxySQL is designed to provide maximal uptime, so here you can change the configuration at runtime and there is no need to restart the server. In the worst case, if ProxySQL crashes, a process has been implemented that monitors and restarts ProxySQL when needed, in order to keep downtimes to a minimum, if they end up occurring.
Real time stats
You can see real time stats of how your queries are routeing or action frequency and performance without any delay. All these details can be explored from stats schema. For example, below is the result of actions performed via ProxySQL:

Takeaways
Configuration
Configuration changes are not persisted after a restart of ProxySQL because changes are saved in the memory. In order to persist the configuration to the disk, you must know which part of the configuration you want to persist and use one of the following commands:
proxySQL> SAVE MYSQL USERS TO DISK
proxySQL> SAVE MYSQL SERVERS TO DISK
proxySQL> SAVE MYSQL QUERY RULES TO DISK
proxySQL> SAVE MYSQL VARIABLES TO DISK
proxySQL> SAVE ADMIN VARIABLES TO DISK
Joins
While restructuring your existing application database, you must remove joins between tables which are planned to place into the different host groups. Remember our example of the big and small table? In that scenario, there should not be any join between large and small tables because these tables are intended to be placed in different host groups.
Prepared statements
ProxySQL doesn’t support prepared statements out of the box. There is already a plan for this but don’t expect it too early or maybe create pull requests 🙂
Update: Experimental support for prepared statement was added in ProxySQL 1.3.0 and can be used now.
Conclusion
With ProxySQL you can have as many different dedicated databases based on the type of data relations. Which now brings more visibility and effectiveness in your MySQL management. Also, think of a situation where one of the resources is affected, but other resources will still be up and working fine.
Hope this helps in understanding how ProxySQL works and how you can benefit from it. If you have any thoughts please share your comments!
The original version of this post appeared at Exotel Engineering Blog.