The Codingdash Test: 12 Steps to Better Engineering
A 2026 update to Joel Spolsky's classic test for evaluating software team health.
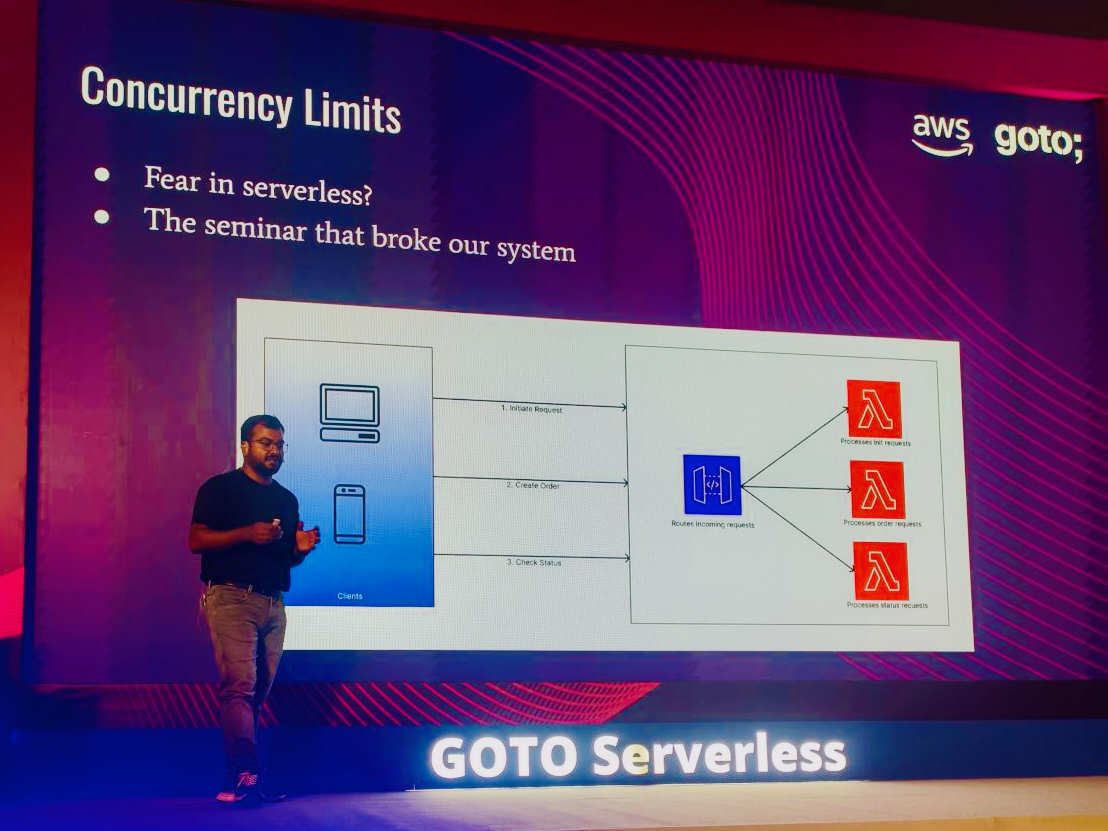
Understanding what your systems are doing in production, from the inside out.
Observability is the property of a system that lets you understand its internal state from its external outputs. In practice, this means logs, metrics, and traces — the three pillars — plus the discipline to instrument your systems well enough that when something goes wrong, you can figure out why without guessing.
The word gets used interchangeably with monitoring, but they’re different ideas. Monitoring tells you when something is wrong. Observability tells you what is wrong and why. A system that alerts on high error rates is monitored. A system that lets you drill into a specific user’s failed request, see every service it touched, measure where the latency came from, and correlate it with a deployment ten minutes earlier — that’s observable.
The shift matters because modern distributed systems produce failure modes that weren’t anticipated at design time. You can monitor for the failures you predicted. Observability is what you need for the ones you didn’t.
Instrumenting well requires upfront investment that pays off unevenly — quietly in the background until the moment a production incident turns a four-hour debugging session into a fifteen-minute fix. That asymmetry makes it easy to deprioritize. Teams that have shipped poorly-instrumented systems into production, and then spent a night blind-guessing at a live incident, tend to instrument the next one better.
Good observability also changes how you develop. When you can see exactly what your code is doing in production, the feedback loop between writing code and understanding its behavior gets much shorter.
2 posts tagged "Observability"
I tweet about tech more than I write about it here 😀